jdivm04:~ # uname -a
Linux jdivm04 5.3.18-lp152.66-default #1 SMP Tue Mar 2 13:18:19 UTC 2021 (73933a3) x86_64 x86_64 x86_64 GNU/Linux
jdivm04:~ # lsb_release -a
LSB Version: n/a
Distributor ID: openSUSE
Description: openSUSE Leap 15.2
Release: 15.2
Codename: n/a
Hi,
Using leap 15.2 and from time in time (usually each 3 months) I ran an update on my linux (zypper ref + zypper up).
I ran on this linux two databases (IBM Informix + mysql) and in the past I already have lot of issues with OOM KILLER.
So, I “disabled” it and haven’t any problem a couple years, until now.
The main solution, which I have set and still set is this configuration on sysctl :
jdivm04:/etc/sysctl.d # sysctl -a | grep overcomm
vm.nr_overcommit_hugepages = 0
vm.overcommit_kbytes = 0
vm.overcommit_memory = 2
vm.overcommit_ratio = 95
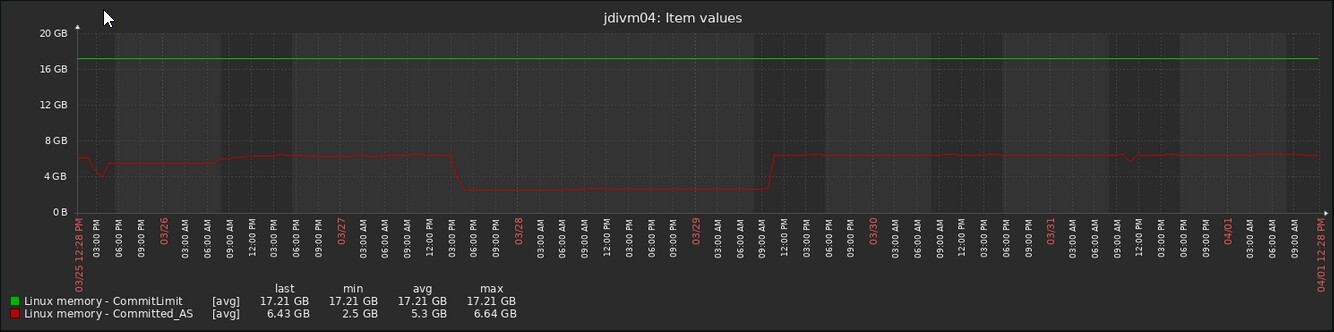
However, three weeks ago I ran my update and then OOM KILLER back in activity, killing with high frequency my databases and others services.
I have all set fine about my memory configuration and I really don’t understand why it still killing them.
The last time it kill the mysql , at dmesg the message finish with this text:
+0.000001] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=mysqld,pid=56172,uid=60
+0.000065] Out of memory: Killed process 56172 (mysqld) total-vm:4673904kB, anon-rss:1218612kB, file-rss:0kB, shmem-rss:8kB
+0.036022] oom_reaper: reaped process 56172 (mysqld), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
I already tried alternative solutions to deactivate it , like below, with no effect:
echo 0 > /sys/fs/cgroup/memory/memory.use_hierarchy
mkdir /sys/fs/cgroup/memory/0
echo 1 > /sys/fs/cgroup/memory/0/memory.oom_control
As far I remember, before the update I was running kernel 5.3.18-lp152.60 or 63, not sure , now is 66. (since I ran new updates to see if solve this behave)
***Any tips how to deactivate for good the OOM KILLER? ***