Following the second thread, I think the procedure would look something like this:
Buy a new 3TB HDD to replace the old one
Download and burn Clonezilla onto an USB stick
Plug the new HDD
Boot up Clonezilla and clone the old HDD onto the new one
Unplug old HDD
…done?
The problem is that the person in the original thread is cloning from a healthy HDD. I don’t know if people use Clonezilla to clone from failing hard drives. On their website, Clonezilla advertizes itself as a recovery tool:
Clonezilla live is suitable for single machine backup and restore.
Clonezilla saves and restores only used blocks in the hard disk.
but I don’t see them explicitly talking about cloning from damaged hard drives.
Is this safe? I don’t expect to recover everything from the HDD, but will Clonezilla be able to at least recover as much as possible without dying in the middle of the process because of a random bad block?
If the used blocks are good, then no problem, because for filesystems it understands, it doesn’t do block-by-block backups.
If used blocks aren’t good, then files are damaged or corrupted, and it will fail at reading those. I don’t recall offhand if it has options to try to recover with multiple reads - that’s something you probably want to ask the Clonezilla folks about in more detail. They have an online discussion area at Clonezilla / Discussion
I like clonezilla but in case of man read errors ddrescue maybe the tool of choice.
But first make a recovery plan and do some trainings with the tools you will use,
From what I’ve read, ddrescue will create an image out of my old HDD. I don’t have anywhere to store a 3TB image, so I’m not sure what I would have to do. Would I have to buy 2 new hard drives?
Thanks, I’ll post there too.
By the way, should I unplug my old hard drive until I’m ready to make the transition to the new one?
While ddrescue can image, it also can do direct disk-to-disk (the only method I can remember ever using), so simply wait until the new arrives and you won’t need “extra” storage space for any image. The backup(s) you already have should suffice to obviate need for a fresh image.
That’s good to know. I’ll take a look at the official documentation, then, but I’d like to know if you have a specific guide you could indicate me. Thanks.
The raw numbers don’t look good, but part of determining the extent of the damage is looking at the error block map as well, or noting in the logs if it’s hitting the same spot many times, or if the damage is more widespread. Raw numbers of errors don’t tell the whole story.
I set everything up, both harddrives connected to the PC and I left ddrescue copying from the old HDD into the new one. Everything seems to be running fine.
I do not like the sound of that. Are either of those disks connected via USB2? Heaven help anyone using 16TB disks at that rate. If not SATA or at least USB3, to me it suggests to expect failure to copy some sectors, but hope for better. Good luck!
Let us know after 10-12 hours or so if it already has done most of the disk and advanced to retries on problem areas, and the extent of remaining problem areas. If you can determine remaining problem areas are limited to unused disk areas (absence of formatted partition(s)), you may have already done all that’s needed even though “completion” not yet reached.
If it was mine I think I’d pop the cover and aim a desk fan at the that HDD’s case location. Room temp here is normally 82F, so all mine run on the warm side of average. I’m lucky when I get as much as 30 months’ life from a UPS battery. They do not like the heat their chargers create, much less elevation from reduced rejection rate.
ETA went down to “only” 4 days earlier today, but now we’re back to 15 days for some reason. In any case, after some adjustments, avg transfer rate went from ~1.5MB/s to ~3MB/s.
I’m running it like this: ddrescue -f -c 16 -a 10M -n /dev/sda /dev/sdc mapfile
Nope. They’re both connected directly to the mb’s sata ports.
It’s been almost 2 full days, so here I am.
lol
The weird thing is that, as slow as it is, zero errors have been reported so far. Which actually checks out with the behavior I was observing: putting aside the NTFS partition, I was able to read from and write into the HDD – it just so happened to be extremely slow.
The old HDD is already sitting on top of my desk outside the PC tower, so there’s not much I can do about that. At least it’s winter over here, so we’re not getting to the usual 40°C (104°F) of the summer.
I’ve looked around the internet for tips about how to try and speed up this process, but honestly I think this is really as good as it gets. I’m hoping just some parts of the disk are slow instead of the whole thing, but I’m not holding my breath.
As I said, the PC tower is sitting on my desk with its guts out because I thought this process would take maybe a day and a night, but I guess I’m gonna put it back together and resume the rescue process with the PC put back together and in place. I’ll report back in a few days.
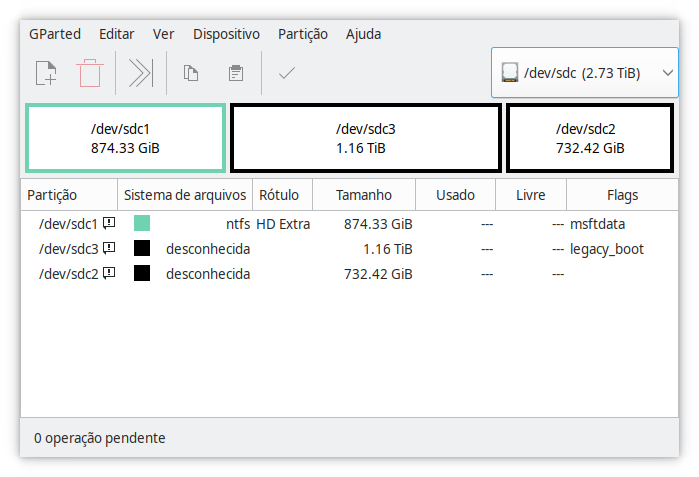
ddrescue just finished copying earlier today, but none of the partitions in the new hard drive are being mounted. In the old hard drive, at least one of the partitions is being mounted successfully, however slow it is. Maybe I should try fscking the new partitions, but I’m afraid I might further damage them and be forced to redo the whole thing again.
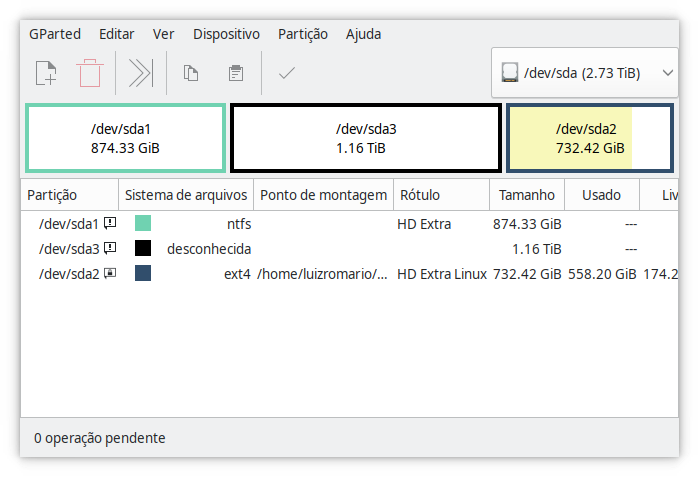
Also, gparted looks like this for the old hard drive:
If you have the original and the clone in the system at the same time you boot, you can’t expect anything to work right. UUIDs and LABELs must be made unique on one or the other first. Neither BIOS nor kernel can be expected to handle ID duplication with any reasonable logic.
Cloning a damaged disk will create a damaged clone. That’s by definition of “clone”. It’s safe regarding further damage due to prolonged use of the damaged disk.
You may try to repair the clone. This can be a tedious undertaking. Some data loss will occur anyway.
A truly safe procedure is restoring from backup. btrfs makes for easy and unobtrusive backups. Ready to use solutions are available: btrbk - Summary