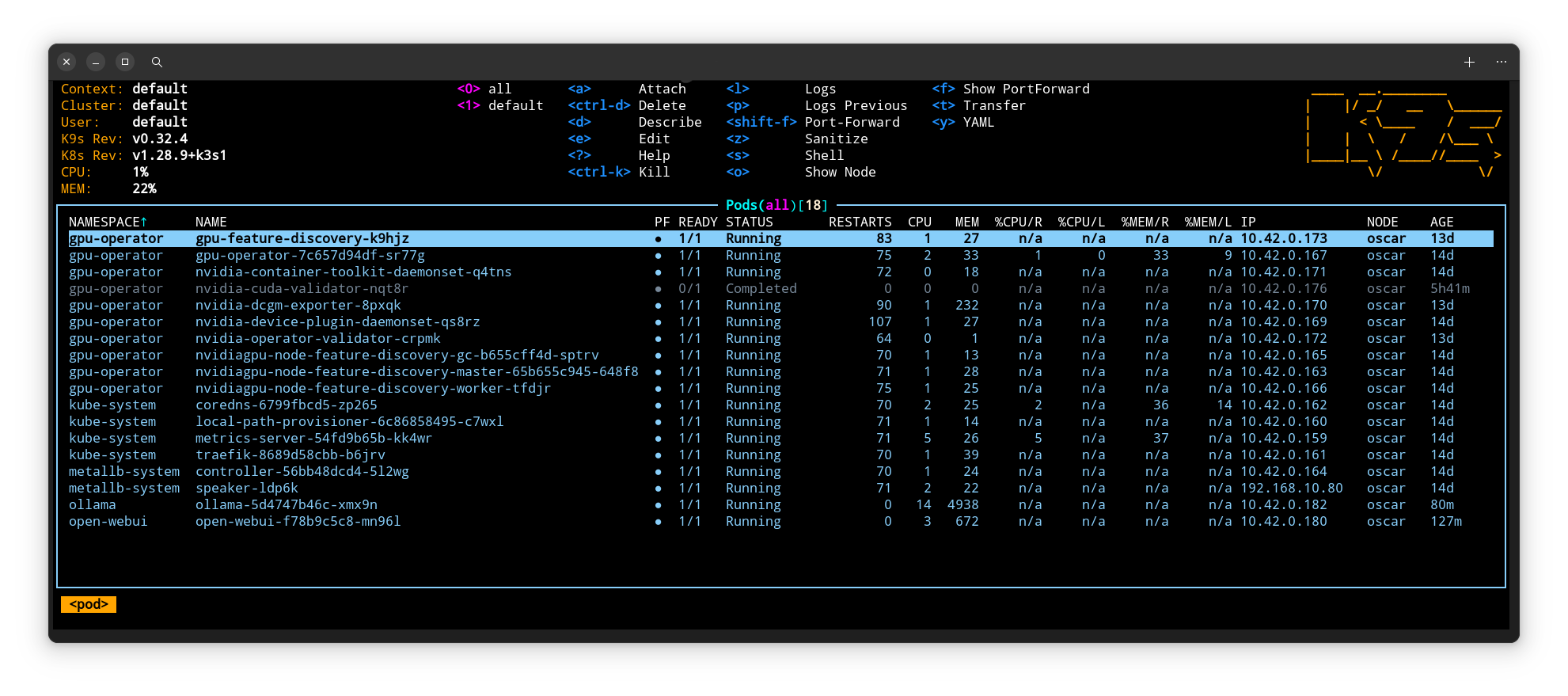
I need to rebuild my setup… But I used Kubernetes and Nvidia container running ollama and open-webui
Low power cpu and RAM, but added a Nvidia Tesla P4 for compute…
Well, I just have the i3-9x AND no dedicated graphics at all. Therefore, your systems seem to be much more powerful than mine. I whish you “Happy using!” — here it’s quite not possible.
with your normal user console:
1 - cd Downloads
2 - curl https://ollama.com/install.sh > install.sh
3 - chmod +x ./install.sh
then with root user:
4 - # sh install.sh
… it should install just fine… wait for it to finish.
then get the deepseek AI models that you want:
5 - # ollama run deepseek-r1:1.5b
other available models (that you might want to try):
deepseek-r1:70b (~40GB BIG model… use it only if you have a decent powerful machine )
deepseek-r1:8b
deepseek-r1:14b
deepseek-r1:32b
6 - download an app so that you can query the AI models in a simple user interface (ChatBox)
(there are for sure other tools available)
side note:
you might want to change the ollama service not to start at boot time… maybe you want it to start manually only (check systemctl status ollama.service) - and change the startup mode if you want
It was my fault, sorry: I have been trying LM Studio and Jan. There, downloads (or imorts of already downloaded files otherwise) are done from within the GUI. I supposed this hold for Chatbox AI, too, which does actually not and has to be done on underliing ollama.
@C7NhtpnK
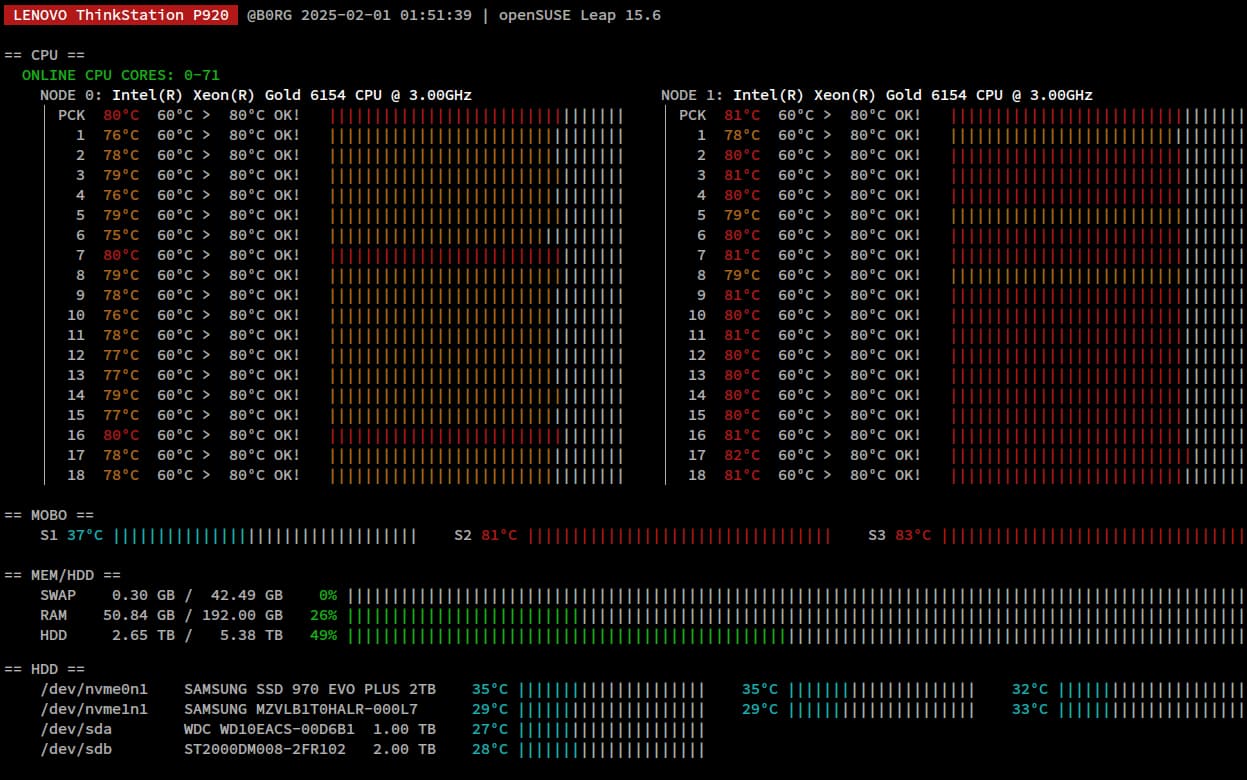
It was custom created by me… (bash script) the print screen is a cut of part of it… it is used to monitor several HW indicators/sensors and it can run in the background without user interface to report indicators and alarms to another system (a database).
BUT, I like to use glances or bpytop (but bpytop interface is not really great with 2 CPU / 72 cores… so it gets messy)